La tragedia de la indexación de datos en Polymarket
Resumen
Bienvenido a la serie “Crypto Tragedy of the Commons” de GCC Research.
En esta serie nos centramos en los principales bienes públicos de la blockchain—los elementos esenciales que sustentan el ecosistema cripto y que empiezan a desviarse de sus principios descentralizados. Si bien estos bienes son la base de Web3, suelen enfrentarse a problemas de incentivos, retos de gobernanza y riesgos de centralización. En este contexto, la brecha entre los ideales de descentralización y la redundancia robusta necesaria para una estabilidad real se encuentra bajo una presión creciente.
En esta edición, analizamos una de las aplicaciones más relevantes de Ethereum: Polymarket y sus herramientas de indexación de datos. Desde principios de este año, Polymarket ha ocupado titulares debido a polémicas como la manipulación de oráculos asociada a las probabilidades electorales de Trump, apuestas sobre tierras raras de Ucrania y pronósticos políticos sobre el color del traje de Zelensky. La magnitud y el alcance de los fondos implicados hacen ineludibles estas disputas.
Pero, ¿ha conseguido este destacado “mercado de predicción descentralizado” alcanzar una descentralización efectiva en la capa de indexación de datos? ¿Por qué infraestructuras descentralizadas como The Graph no han cumplido con lo esperado? ¿Cómo debería ser una solución pública de indexación de datos que resulte realmente útil y sostenible?
I. El efecto dominó de una caída en una plataforma de datos centralizada
En julio de 2024, Goldsky—una infraestructura de datos blockchain en tiempo real para desarrolladores de Web3 que ofrece indexación, subgraphs y datos en streaming—sufrió una interrupción de seis horas. Esto paralizó parte relevante del ecosistema de Ethereum: las interfaces DeFi dejaron de mostrar posiciones y saldos de los usuarios, mercados de predicción como Polymarket no podían reflejar información veraz y, para los usuarios, muchas interfaces de proyectos resultaron inutilizables.
Precisamente eso es lo que las aplicaciones descentralizadas deberían evitar. El diseño blockchain se concibió, ante todo, para eliminar puntos únicos de fallo. El incidente de Goldsky reveló una realidad preocupante: aunque las blockchains están diseñadas para la descentralización, buena parte de la infraestructura que da soporte a las aplicaciones on-chain sigue siendo altamente centralizada.
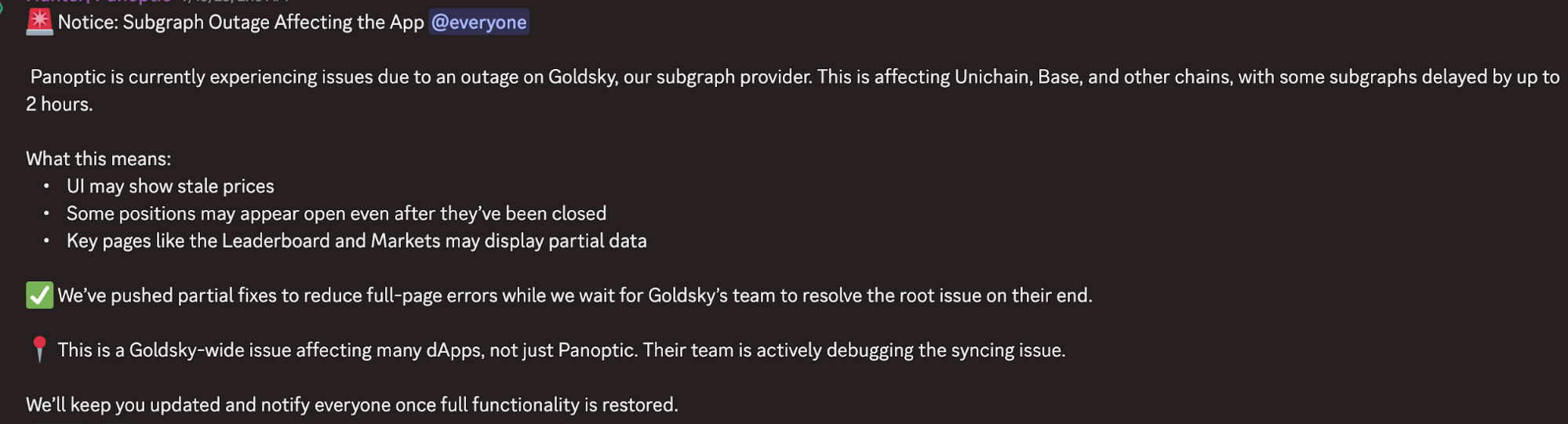
La raíz del problema está en que el indexado y la consulta de datos blockchain son bienes públicos digitales—no excluyentes, no rivales—y los usuarios tienden a esperar acceso gratuito o casi gratuito. Sin embargo, sostener esta infraestructura exige inversión constante en hardware, almacenamiento, ancho de banda e ingeniería. Sin un modelo de ingresos sostenible, el sector evoluciona hacia una dinámica de “el ganador se lo lleva todo”: cuando un proveedor alcanza ventaja en velocidad y capital, los desarrolladores derivan toda su carga de consultas a ese proveedor, y surge un nuevo punto único de dependencia. Gitcoin y otras organizaciones sin ánimo de lucro han recordado reiteradamente que “la infraestructura open source crea valor multimillonario, pero sus creadores a menudo ni siquiera pueden pagar su hipoteca”.
La conclusión es evidente: el ecosistema descentralizado requiere intervenciones urgentes—financiación de bienes públicos, redistribución de incentivos o modelos gestionados por la comunidad—para diversificar la infraestructura de Web3 y evitar nuevos riesgos de centralización. Instamos a los desarrolladores de DApps a adoptar estrategias local-first, y a las comunidades técnicas a diseñar DApps que gestionen con flexibilidad caídas de indexadores—asegurando que los usuarios puedan interactuar incluso si los servicios de indexado están inactivos.
II. ¿De dónde proceden realmente los datos de tu DApp?
Para comprender incidentes como el de Goldsky, debemos analizar en mayor profundidad el funcionamiento de las DApps. La mayoría de usuarios percibe solo dos componentes: el contrato desplegado en la cadena y la interfaz de usuario. Acostumbran a consultar Etherscan para verificar el estado de las transacciones, visualizar información en el frontend y realizar operaciones a través de la interfaz. Pero, ¿exactamente de dónde obtiene el frontend sus datos?
El papel crítico de los servicios de recuperación de datos
Supongamos que desarrollas un protocolo de préstamos que muestra posiciones, márgenes y deudas de los usuarios. Un planteamiento ingenuo consistiría en que el frontend consultara estos datos directamente de la blockchain. Sin embargo, la mayoría de contratos no permite consultar todas las posiciones de una dirección—solo por ID de posición. Así, para mostrar las posiciones de un usuario, habría que recuperar primero todas las posiciones abiertas y después filtrarlas manualmente—como buscar manualmente entre millones de asientos en un libro mayor. Es técnicamente viable, pero extremadamente lento e ineficiente. De hecho, incluso en servidores backend, proyectos DeFi de gran escala pueden tardar horas en recuperar estos datos desde un nodo local.
En este punto, la infraestructura especializada resulta indispensable. Proveedores como Goldsky ofrecen servicios de indexación que aceleran enormemente el acceso a los datos. El esquema siguiente muestra los tipos de información que estos servicios facilitan a las aplicaciones.

Algunos lectores pueden preguntarse: ¿no ofrece The Graph una recuperación de datos descentralizada para Ethereum? ¿En qué difiere de Goldsky y por qué muchos proyectos DeFi prefieren Goldsky antes que The Graph?
Cómo se relacionan The Graph, Goldsky y SubGraph
Para clarificarlo, desglosamos los conceptos clave:
- SubGraph es un framework para desarrolladores. Permite crear código que lee y agrega datos on-chain para su visualización en el frontend.
- The Graph es una plataforma de recuperación de datos descentralizada líder, que desarrolló el framework SubGraph sobre AssemblyScript. Los desarrolladores emplean SubGraph para capturar eventos de contrato y almacenarlos en una base de datos, consultable vía GraphQL o SQL.
- Los servicios que ejecutan SubGraphs se denominan operadores de SubGraph. Tanto The Graph como Goldsky actúan como proveedores gestionados de SubGraph, ya que el código finalmente se ejecuta en servidores. Así lo explica la documentación de Goldsky:
¿Por qué existen diferentes operadores de SubGraph?
Porque el framework define únicamente cómo extraer datos de los bloques y volcarlos en bases de datos, pero no los mecanismos concretos de flujo ni la salida de los datos. Cada operador desarrolla estos detalles según sus propios criterios.
Los operadores pueden aplicar modificaciones personalizadas de nodo y optimizaciones de rendimiento. The Graph ha incorporado Firehouse para acelerar el indexado; Goldsky mantiene cerrado el runtime principal de SubGraph.
En la práctica, The Graph es un centro descentralizado de operadores de SubGraph. Por ejemplo, el subgraph de Uniswap v3 lo mantienen múltiples operadores, lo que convierte a The Graph en una especie de marketplace colectivo donde los usuarios pueden presentar código SubGraph y varios operadores atenderán su consulta.
Modelo de precios de Goldsky
Goldsky, como servicio SaaS centralizado, emplea el conocido modelo de pago por recursos. La mayoría de ingenieros están familiarizados con este enfoque. Así es la calculadora de precios de Goldsky:
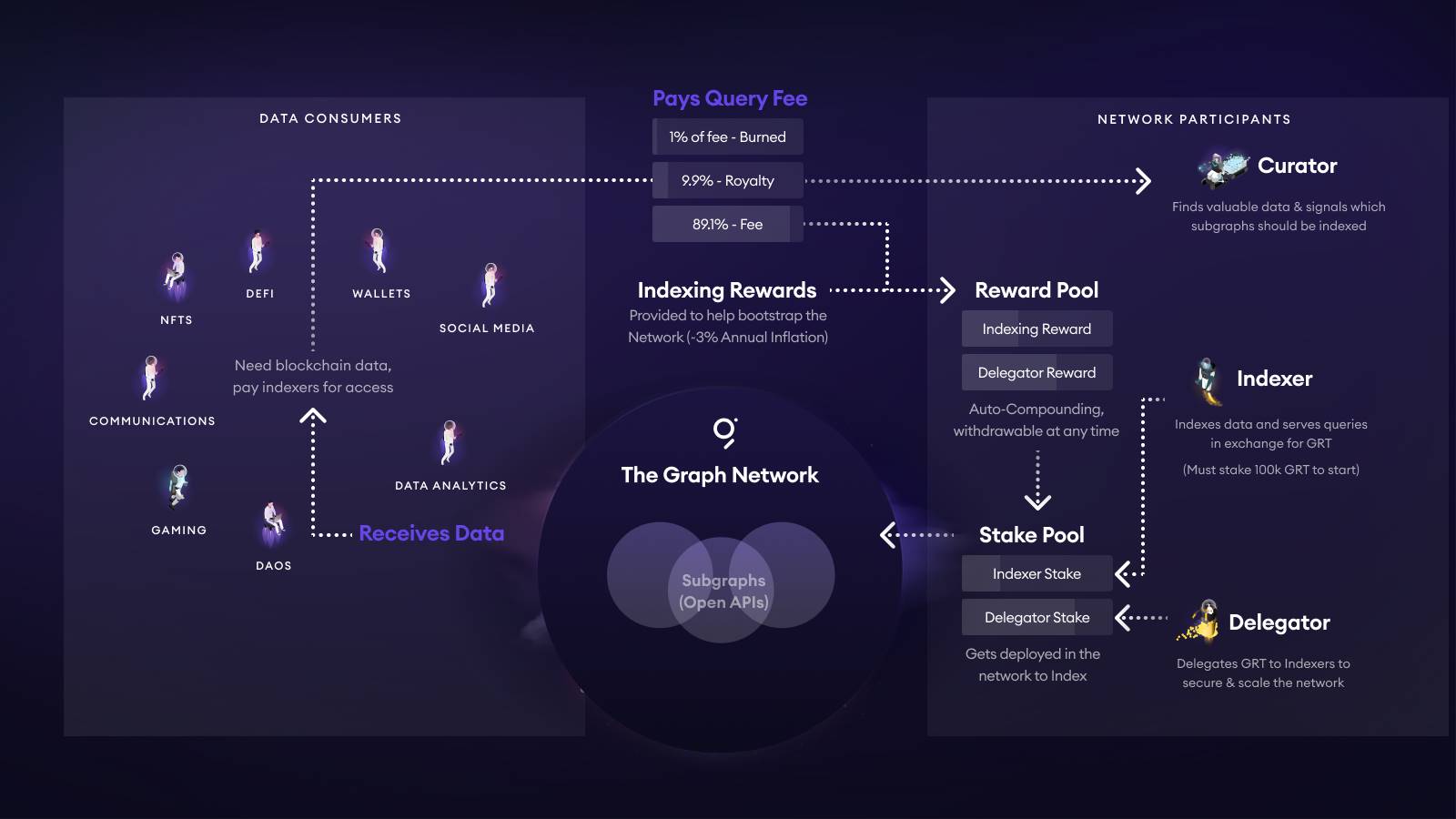
Modelo de precios de The Graph
El modelo de The Graph es singular: las comisiones por consulta e incentivos se integran en la tokenomía de GRT. Así funciona:
- Cada consulta a un SubGraph reparte las tarifas así: se quema un 1% de GRT; el 10% se destina a la pool de curadores (normalmente desarrolladores); y aproximadamente el 89% lo reciben Indexers y Delegators según algoritmo.
- Los Indexers deben bloquear un mínimo de 100.000 GRT para participar, y son penalizados si entregan resultados incorrectos. Los Delegators delegan GRT en Indexers para acceder a la parte correspondiente del 89% del fondo de recompensas.
- Los Curators (a menudo desarrolladores) “señalizan” su interés apostando GRT sobre una bonding curve específica para su SubGraph. A mayor staking de GRT, más recursos de Indexer pueden atraer. Se recomienda apostar entre 5.000 y 10.000 GRT para garantizar la indexación.
Tarifas de consulta:
Para consultar The Graph, los desarrolladores deben obtener una clave de API y prepagar GRT, que se descuenta por cada solicitud.
Comisiones de señalización:
Para que un SubGraph sea indexado, el desarrollador debe apostar GRT para “señalizar” valor y atraer operadores. Solo cuando se alcanza un determinado nivel de staking (ej. 10.000 GRT), los Indexers recogen el SubGraph para su uso productivo.
Durante la fase de pruebas, los SubGraphs pueden desplegarse sin coste con el operador de staging de The Graph, pero este no se recomienda para producción. Para producción, los SubGraphs han de publicarse en red y los Indexers deciden, en función de las señales, cuál indexar voluntariamente.
¿Por qué desarrolladores y departamentos financieros rechazan la tarificación por tokens?
Para la mayoría de proyectos, el proceso de The Graph resulta engorroso. Aunque para equipos avanzados adquirir GRT es sencillo, el procedimiento de curación es lento e incierto. Destacan dos grandes problemas:
- Incertidumbre: los desarrolladores carecen de referencias claras sobre cuánto GRT deberán apostar ni cuánto tiempo tardarán los Indexers en aceptar su SubGraph.
- Complejidad contable: el modelo de precios basado en tokenomía dificulta la gestión de costes para empresas y contabilidades.
¿Centralizar es más sencillo?
Para la mayoría de desarrolladores, Goldsky resulta simplemente más práctico: el precio es previsible, el servicio se activa inmediatamente tras el pago y la incertidumbre es mínima. Esto ha propiciado una dependencia excesiva de un solo proveedor de indexado en Web3.
La tokenomía GRT de The Graph puede estar bien diseñada, pero su complejidad desincentiva su uso y no debería repercutirse en el usuario final—el staking para curación, especialmente, debería estar oculto tras una capa de pago sencilla.
No es solo una opinión: Paul Razvan Berg, ingeniero de smart contracts y fundador de Sablier, criticó públicamente la experiencia con SubGraph y el pago en GRT como extremadamente deficiente.
III. Soluciones actuales ante caídas de indexadores de datos
¿Cómo debería reaccionar el ecosistema ante los puntos únicos de fallo en el indexado? Como hemos repasado, los desarrolladores pueden emplear The Graph, aunque deben enfrentarse al staking y curación de GRT para acceder a la API.
En el ecosistema EVM existen varias alternativas para el indexado de datos. Pueden consultarse referencias como The State of EVM Indexing de Dune, Overview of EVM Indexing Tools de rindexer, y este hilo reciente.
Este artículo no profundiza en la causa técnica de la caída de Goldsky; según su informe, la compañía solo comparte detalles con clientes empresariales. Según indican, el problema surgió escribiendo datos indexados en la base de datos, restaurándose el acceso tras colaboración con AWS.
Existen otras alternativas:
- ponder es una herramienta de indexado de datos sencilla, intuitiva y fácil de desplegar, que permite a los desarrolladores autoalojarla en infraestructuras propias.
- local-first es una filosofía de desarrollo que sostiene que las DApps deben seguir siendo usables incluso sin conexión a la red. En blockchain, esto implica que el usuario debe disfrutar de una experiencia eficiente siempre que pueda acceder a la cadena, independientemente de que los indexadores estén disponibles.
Ponder: indexación de datos DIY
¿Por qué recomendar ponder?
- Sin bloqueo de proveedor: nacida de un desarrollador independiente, ponder solo precisa un endpoint RPC de Ethereum y una base de datos Postgres—sin servicios gestionados.
- Excelente experiencia para el programador: desarrollada en TypeScript y la librería Viem, ponder resulta cómoda de utilizar (el autor la ha utilizado en profundidad).
- Rendimiento sobresaliente.
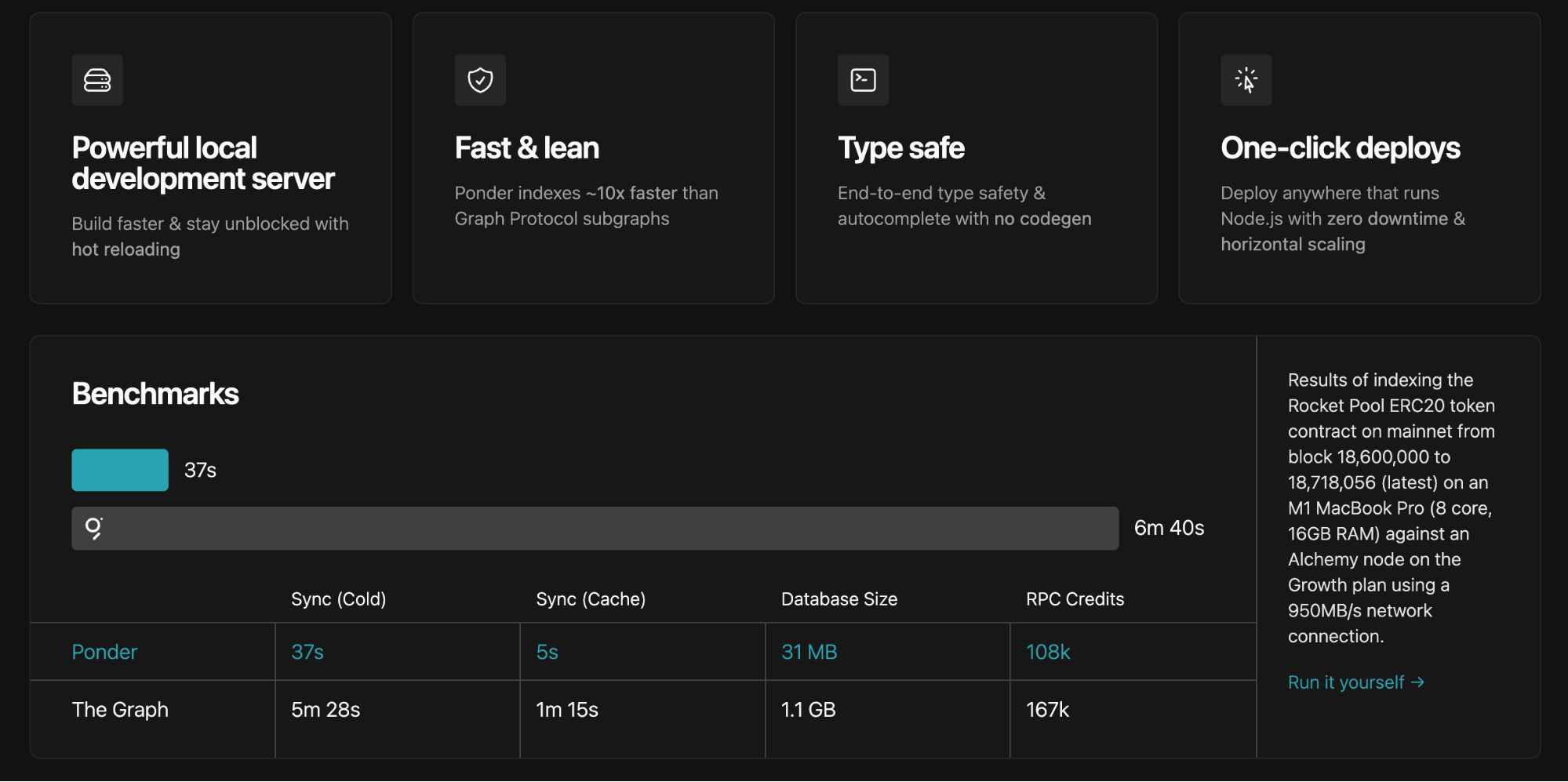
Tiene, eso sí, algunos inconvenientes: ponder evoluciona rápidamente, lo que puede originar incompatibilidades en implementaciones antiguas. Para detalles técnicos y mejores prácticas, consulte la documentación oficial.
Resulta relevante que ponder está introduciendo un modelo comercial en línea con la “teoría de separación” explicada en un artículo anterior.
En resumen: los bienes públicos benefician a todos, pero cobrar por ellos puede reducir el bienestar colectivo al excluir usuarios marginales (lo que no es óptimo de Pareto). La tarificación diferenciada podría maximizar el excedente, pero es costosa y compleja de implementar. La teoría de separación propone aislar un subgrupo homogéneo, cobrando solo a este segmento y permitiendo el acceso gratuito al resto.
Aplicación de ponder a esta teoría:
- El despliegue requiere conocimientos técnicos—el desarrollador debe gestionar dependencias externas (endpoint RPC, base de datos).
- El mantenimiento es continuado (por ejemplo, emplear proxies para balancear carga y asegurar la recuperación de datos concurrentes), lo que puede resultar complicado para algunos desarrolladores.
- Ponder ofrece ahora un despliegue automatizado en fase beta vía Marble: el usuario envía su código a la plataforma y despliega con un solo clic.
Este enfoque “separa” a los usuarios que priorizan la comodidad—quienes pagan por la solución gestionada de Marble—mientras que quienes prefieren la autogestión pueden seguir utilizando ponder gratuitamente.
Comparativa entre ponder y la adopción de Goldsky:
- Herramientas verdaderamente permissionless y autoalojadas como ponder gozan de popularidad en proyectos pequeños que buscan autonomía y flexibilidad.
- Grandes proyectos con altas demandas de rendimiento optan por servicios gestionados como Goldsky, que proporcionan mayor disponibilidad y redundancia.
Ambos modelos conllevan riesgos. El incidente de Goldsky demuestra la conveniencia de mantener un indexador ponder propio como solución de respaldo. También es recomendable validar las respuestas de RPC cuando se emplea ponder: hace poco, safe informó de un incidente en el que datos inválidos de RPC provocaron la caída del indexador. No hay evidencias de que el fallo de Goldsky se debiera a problemas de RPC, pero es un factor que no se puede descartar.

Paradigma local-first en el desarrollo
El modelo local-first ha despertado gran interés en los últimos años. Se basa principalmente en dos principios:
- Disponibilidad sin conexión
- Colaboración entre clientes
En la literatura técnica local-first se mencionan con frecuencia los CRDT (Conflict-free Replicated Data Types), estructuras de datos que resuelven automáticamente los conflictos en edición colaborativa distribuida. Actúan, en esencia, como protocolos ligeros de consenso que mantienen la consistencia de datos entre dispositivos.
En el desarrollo blockchain, estos requisitos pueden flexibilizarse: el objetivo fundamental es que el usuario mantenga una funcionalidad mínima incluso cuando los indexadores backend no estén disponibles, ya que la cadena garantiza la consistencia entre actores.
En la práctica, una DApp local-first puede:
- Almacenar en caché información clave—saldos, posiciones—para que el usuario vea siempre su último estado conocido, incluso sin indexador.
- Degradar funcionalmente de forma controlada—recuperar datos esenciales directamente de RPC si los indexadores fallan, permitiendo ver parte de la información de la cadena en tiempo real.
Este enfoque multiplica la resiliencia de la aplicación. En el escenario ideal, la mejor DApp local-first invitaría al usuario a ejecutar un nodo local y consultar los datos a través de herramientas como TrueBlocks. Para profundizar en indexado descentralizado y local, véase el hilo Literally no one cares about decentralized frontends and indexers.
IV. Conclusión
La caída de Goldsky durante seis horas ha sido una señal de alarma para todo el ecosistema Web3. Aunque las blockchains son de por sí resilientes y descentralizadas, la mayoría de proyectos en la capa de aplicación sigue basándose en infraestructuras centralizadas de datos—exponiendo el sistema a nuevas amenazas sistémicas.
Este artículo ha expuesto por qué The Graph—pese a su reconocimiento—ha sufrido obstáculos de adopción por la complejidad de la tokenomía GRT y la fricción para los desarrolladores. También hemos analizado estrategias para disponer de indexado de datos más robusto—sugiriendo el uso de marcos autoalojados como ponder como respaldo y destacando la vía comercial innovadora seguida por ponder. Finalmente, hemos tratado el paradigma local-first, animando a los desarrolladores de DApps a asegurar la usabilidad incluso cuando los indexadores estén inactivos.
Cada vez más, los desarrolladores Web3 identifican los puntos únicos de fallo en el indexado de datos como una vulnerabilidad crítica. Desde GCC animamos a toda la comunidad a centrar sus esfuerzos en este reto de infraestructura, experimentando con indexadores de datos descentralizados y diseñando DApps cuyos frontends sigan funcionando aunque los indexadores estén fuera de línea.
Aviso legal:
- Artículo republicado de TechFlow. Los derechos de autor permanecen en el autor original, shew. Ante cualquier cuestión sobre esta republicación, por favor contacte con el equipo de Gate Learn para su resolución.
- Aviso: Las opiniones aquí expresadas pertenecen únicamente al autor y no constituyen asesoramiento de inversión.
- Las traducciones realizadas por el equipo de Gate Learn no pueden reproducirse, distribuirse ni plagiarse sin la debida atribución a Gate.com.
Artículos relacionados

¿Qué es Tronscan y cómo puedes usarlo en 2025?

¿Qué es SegWit?

Todo lo que necesitas saber sobre Blockchain

¿Qué hace que Blockchain sea inmutable?

¿Qué es Stablecoin?
